Morgan Gautherot
Je suis
Passionné par la data et le machine learning, j'ai de nombreuses casquettes, je suis docteur, formateur, Youtuber et organisateur de conférences.
Mon objectif est de vous aider à résoudre vos problèmes professionnels en exploitant le potentiel des données.
Je suis déterminé à partager mes connaissances et à contribuer à la réussite des entreprises grâce aux données.
Ensemble, nous pouvons façonner un avenir plus intelligent.
Experience
Projet : Créer des modèles pour estimer l’efficacité énergétique d’un logement
Contexte : Leroy Merlin est le leader français du marché de l'aménagement de la maison. La mission de l'entreprise est de rendre l'habitat plus accessible et plus durable. Dans cette optique, l'entreprise intègre à son site web un simulateur capable d'estimer la performance énergétique de chaque logement. L'objectif est de pouvoir suggérer des améliorations concrètes pour améliorer le confort de vie et contribuer à l'effort de réduction de la consommation d'énergie.
Missions:- Analyser les données externes.
- Intégrer les données ouvertes dans les systèmes d'information.
- Création d'un modèle de prédiction de la performance énergétique d'un bâtiment (DPE, GES, déperdition de chaleur, etc.).
- Création d'une API pour mettre le modèle à disposition du front-end.
- Gestion du cycle de vie d'un modèle d'apprentissage automatique.
- Proactif sur la vision business du produit.
Environnement Technique : Google Cloud Plateforme, BigQuery, FastAPI, Python, SQL, TensorFlow, Pytest, Github
Professeur associé
Ecole : ISEN, EDHEC, IAE, Polytech Lille
Université : Université de Lille, Dakar institute of Technology
Institut de formation : ORSYS, Jedha
Création de contenus pédagogiques et évaluation de compétences sur les thèmes suivants :- Machine learning
- Deep learning
- Data science
- Computer vision
- Natural language processing
Digital Nomade
Contexte : De janvier à juillet, j'ai exploré la région de l'Océanie, visitant la Nouvelle-Zélande, la Tasmanie, l'Australie, les Fidji et la Nouvelle-Calédonie. C'était l'occasion pour moi d'expérimenter le mode de vie de nomade digital, me permettant de travailler tout en voyageant. J'ai réussi à accomplir diverses missions de courtes durées, qu'elles soient de prestation de service, de conseil ou de formation. Ci-dessous une liste non exhaustive des missions que j’ai pu réaliser.
Tools: Python, Flask, SQLAlchemy, Render, Github Action, Flake8, Black, TensorFlow, Pytest
ADEO
Projet 1 : Etudes des nouveaux jeux de données
Contexte : Les entrepôts Leroy Merlin reçoivent chaque jour des centaines de colis. Tous ne sont pas contrôlés. Si des colis acceptés font défaut, la perte est pour Leroy Merlin. Pourtant tous les colis ne peuvent pas être contrôlés car seul une faible quantité fait défaut. Un modèle a été créé pour déterminer si un colis doit être contrôlé. Le POC a été mis très récemment en production pour des magasins tests et doit être étendu à de nouveaux pays.
Missions:
- Collecter, nettoyer et orchestrer les pipelines de données pour les nouveaux pays,
- Examiner les données en collaboration avec les équipes métiers en vue d'améliorer leur qualité.
- Etudier les nouvelles sources de données disponibles,
Projet 2 : Mis-à-jour du modèle de prédiction
Contexte : Les entrepôts Leroy Merlin reçoivent chaque jour des centaines de colis. Tous ne sont pas contrôlés. Si des colis acceptés font défaut, la perte est pour Leroy Merlin. Pourtant tous les colis ne peuvent pas être contrôlés car seul une faible quantité fait défaut. Un modèle a été créé pour déterminer si un colis doit être contrôlé. Même si ROI du modèle est positif et suivit chaque semaine, le modèle n’a pas été mis à jour ni contrôlé depuis sa mise en production.
Missions:
- Monitoring des performances du modèle au cours du temps,
- Diagnostic des drifts dans les données,
- Amélioration des performance du modèle,
- Mise en production du nouveau modèle.
Tools: Google Cloud Plateforme, BigQuery, FastAPI, Python, SQL, Kafka, Docker, Airflow, Colibra
CHRU Lille
Projet 1 : Modèle de prédiction de la dégradation de patient Alzheimer
Contexte : Les patients atteints de la maladie d’Alzheimer subissent des dégradations cognitives hétérogènes et difficilement prévisible à l’échelle individuelle. L’objectif est de créer un modèle capable de déterminer la dégradation future d’un patient Alzheimer à partir de ces données cliniques et d’imageries.
Missions:
- Charger d’extraire les données utiles à partir des images IRM du patient,
- Analyser les données cliniques et imageries du patient,
- Trouver la variable cible (ici la pente de décroissance du MMSE qui évalue l’état cognitif du patient),
- Entraînement de modèle de machine learning pour prédiction la pente du MMSE de chaque patient (Random Forest, Gradient Boosting Tree, SVM, régression linéaire),
- Gestion de projet,
- Rédaction de documentation techniques du projet et d’un article de recherche.
Projet 2 : Mis-à-jour du modèle de prédiction
Contexte : Aujourd’hui les patients victimes de catatonie sont peu pris en charge et les traitements associés sont peu voire pas efficaces. La benzodiazépine est un médicament censé soigner ses troubles, mais les patients ne répondent pas tous au traitement. L’objectif est de créer un modèle capable de déterminer à l’avance si un patient est répondeur au traitement au non à partir de ces données cliniques et d’imageries.
Missions:
- Charger d’extraire les données utiles à partir des images IRM du patient,
- Analyser les données cliniques et imageries du patient,
- Entraînement de modèle de machine learning pour prédire la réponse de chaque patient (Random Forest, Gradient Boosting Tree, SVM, régression linéaire),
- Gestion de projet,
- Rédaction de documentation techniques du projet et d’un article de recherche.
Tools: Python, Sklearn, Pandas, Numpy, Linux, Git
Projet 3 :Segmentation de l’hypothalamus
Contexte : Pour évaluer l’évolution de maladie neurologique, les neurologues doivent pouvoir contrôler le volume de régions cérébrales au cours du temps. Certaines régions comme l’hypothalamus sont très petites. Il est donc difficile d’obtenir une segmentation automatique de ces régions avec les méthodes classiques. Des radiologues doivent donc segmenter manuellement les images, ce qui est une tâche longue et fastidieuse. L’objectif est de créer un modèle d’apprentissage profond capable de segmenter automatiquement la région de l’hypothalamus.
Missions:
- Chargé de traiter et homogénéiser les images IRM,
- Analyser les données d’imageries,
- Implémentation de nombreuses fonctions de data augmentation,
- Entraînement de modèle de deep learning,
- Gestion de projet,
- Rédaction de documentation techniques du projet et d’un article de recherche.
Tools: Python, Sklearn, Pandas, Numpy, Linux, Github, Keras, TensorFlow
General Electric
Contexte : General Electric Healthcare, est un des trois plus grands constructeurs d’IRM au monde. Depuis quelques années, les innovations des IRMs ne sont plus exclusivement techniques mais aussi dues à l’intégration de logiciels d’intelligence artificielle d’aide à la décision. Ces logiciels permettent d’aider les radiologues à obtenir une image de meilleure qualité, plus rapidement et d’obtenir des biomarqueurs associés à l’image. Un de ces biomarqueurs est l’âge cérébral qui permet de quantifier la santé cérébrale d’un individu. L’objectif était de développer un modèle de prédiction de l’âge cérébral capable de prédire la santé cérébrale à l’échelle individuelle.
Missions:
- Chargé de traiter et homogénéiser les images IRM,
- Analyser les données d’imageries,
- Implémentation de nombreuses fonctions de data augmentation,
- Entraînement de modèle de deep learning,
- Gestion de projet,
- Rédaction de documentation techniques du projet et d’un article de recherche.
Tools: Python, Sklearn, Pandas, Numpy, keras, Tensorflow, Linux, Git
Decathlon
Contexte : Decathlon est un des leaders de la grande distribution de sport et loisirs. L’objectif de l’équipe data science est de tirer parti de la donnée pour aider les métiers du commerce, de l’offre et de la logistique dans leurs actions de tous les jours.
Missions:
- Elaboration de modèle d’association à base de graphes,
- Prédiction de sport pratiqué grâce à la consommation des clients,
- Prévision de ventes à la semaine sur 1 an,
- Prototypages, test et mise en production des solutions.
Tools: Python, Sklearn, Pandas, Numpy, keras, tensorflow, Linux, git, dash, Rshiny, Spark, AWS
Projets
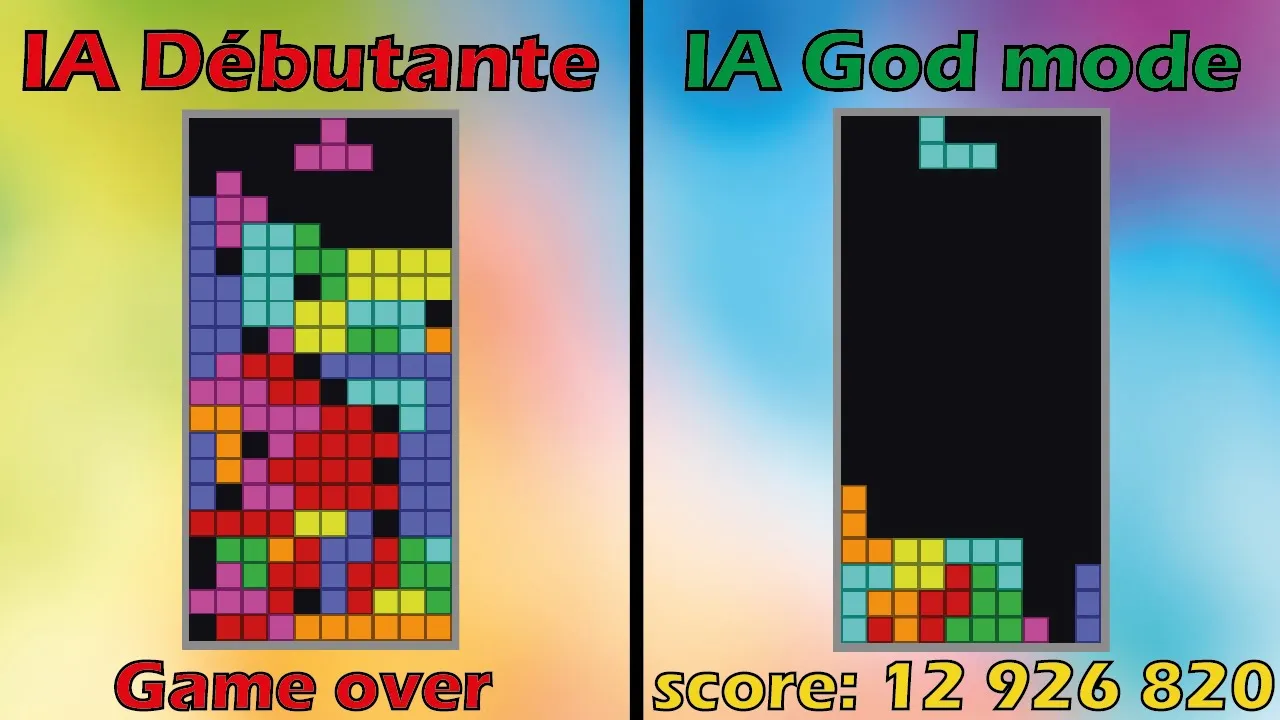
Entraînement d'un modèle de deep learning capable de battre le champion du monde de Tetris



Compétences
Languages
 HTML5
HTML5
 CSS3
CSS3
Manipulation des données
Machine learning
Cloud
Visualisation des données
Tests
API
Prototype web
Orchestrateur
Gestion du code
Formation
Ingénieur en informatique et statistique
Polytech Lille
-
Cours pertinents :
- Statistique
- Probabilité
- Machine learning
- Théorie des graphes
- Développement informatique